

文|肖漫
裁剪|李勤
尊龙凯时中国官方入口6月18日,蔚来同期向两代平台车型(包含8款NT2.0平台车型、4款NT2.5平台车型,以及6款NT3.0车型)推送了最新版的天下模子,这意味着,蔚来当今能让消释套复杂的智驾代码,当今能跑在不同代际的芯片上。
软件迭代节拍被硬件勒诈曾是一个困扰行业的不毛。许多车企无法在不同版块、建立的车型上迭代消释款软件,这带来的截止是,很永劫刻内惟有使用最新版块硬件的车才调用上最佳的软件,老车主被背刺。
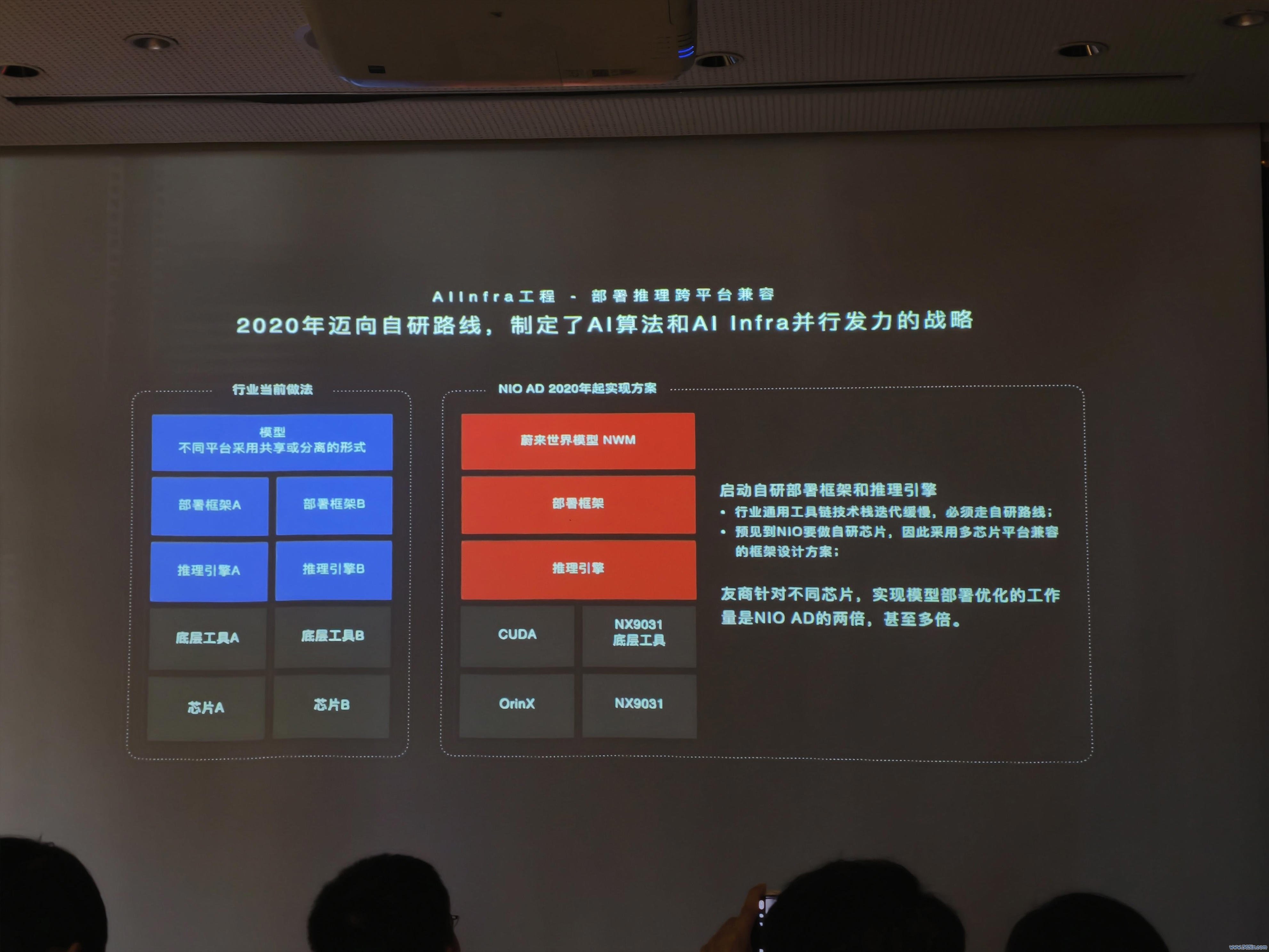
蔚来部署推理跨平台兼容
任少卿的团队在 2020 年就在想考如那儿罚这个问题。蔚来的作念法是搭建一套AI Infra——自研器具链铺平不同芯片间的边界,用AI编译器进步车辆的处理速率,用 AI Agent 自动化串联全经过。
那时业内主流的作念法如故用英伟达的器具进行表层部署。但那时的蔚来判断,车端芯片的工程架构会不绝快速迭代,主流的架构仅能用 3-5 年。基于这一判断,蔚来决定只保留最底层的硬件接口层(如 CUDA),在此之上全面自研表层部署软件,包括推理引擎、部署框架。
另外,和大多数自研芯片的主机厂同样,蔚来也自研了编译器,竣事了自动算子优化,将正本需要 1-2 周的部署时刻镌汰至 1-2 天,同期让端侧的推感性能进步 20% 以上。
任少卿显现,蔚来曾经经引入 AI Agent 的自动化责任流,收受了正本需要工程师永劫刻在电脑前手动盯盘、分散实践的繁琐经过,将一次好意思满的模子上车部署时刻从一天致使数天,极速压缩到 2 小时以内。
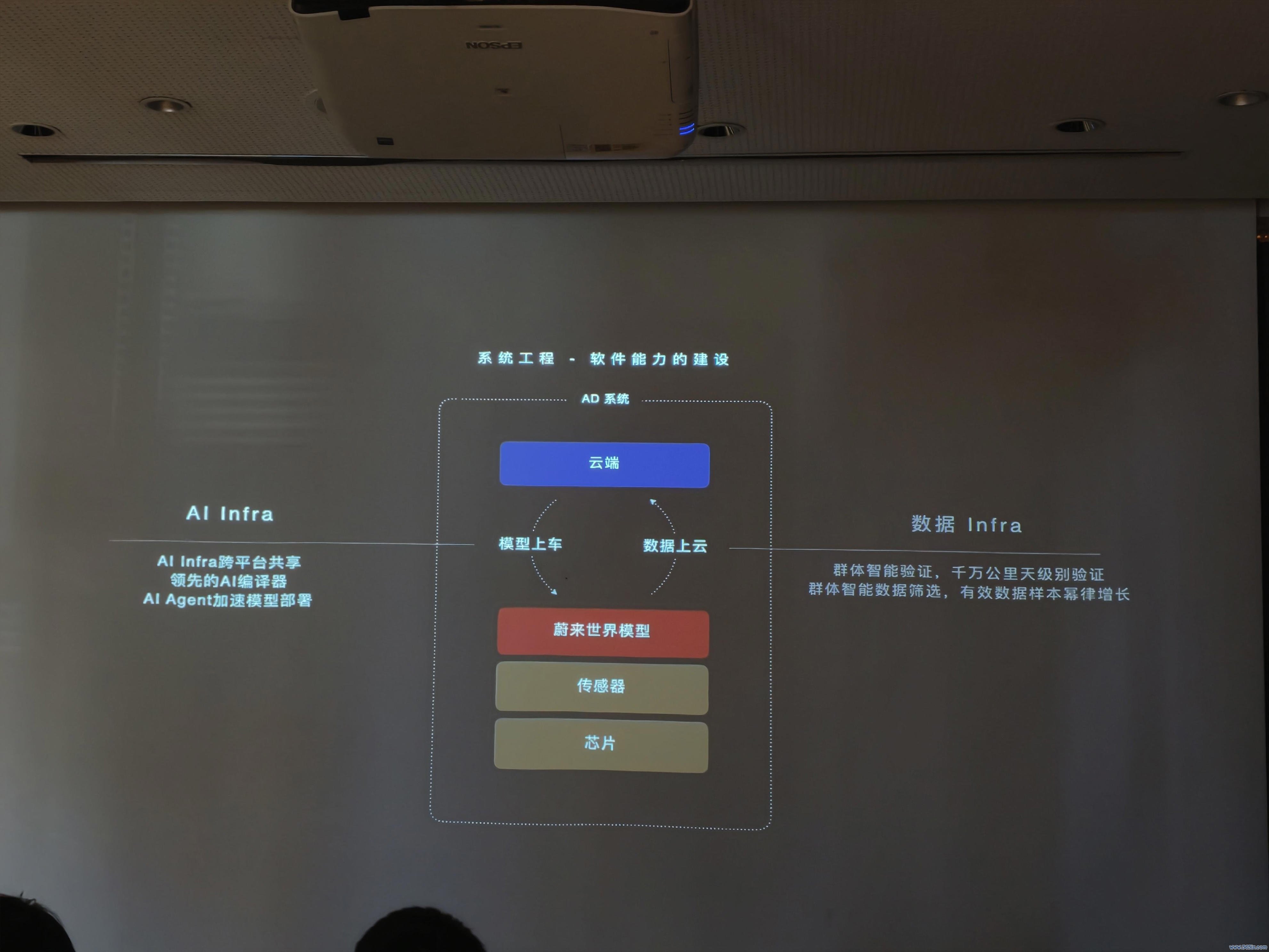
蔚来智驾软件智商开导
AI Infra 竣事模子快速上车,车端在实践诓骗场景中集合高价值数据回传磨砺,算法团队用这些数据磨砺出更灵敏的模子后,再次交给 AI Infra 活水线去打包上车,竣事数据闭环。
任少卿直言:“在大模子时期,性能进步三个点,数据需要翻十倍;如果想进步18个点,数据则需要10倍的六次方”。也等于说,如果单靠增多专职测试车队、费钱采集物理数据,很快就会波及老本和领域的物理极限。
对于数据的长入,任少卿认为“数据的骨子是算力,是‘模子+算力’运行产生的截止”。
蔚来在量产车型上以“影子模式”运行最新的待考证大模子,不滋扰用户驾驶,只作念及时推演,一朝模子的判断与东说念主类确切驾驶算作发生不合,就把这个Corner Case 传回云表。
这种考证体系能跳动 NT2 和 NT3 平台,每周无感完成超 4000 万公里的主动安全测试,这特地于 1000 辆测试车连轴跑一年的数据量。

蔚来数据Infra工程
任少卿认为,这种通过车端筛选出的 Corner Case,在总体数据量中可能只占 5%,但它提供的磨砺价值却比底层老例数据还要大。
另外,在云表天下模子中,蔚来会有意给 AI 制造多样极点且违背老例的罗网,免强神经集合学习如安在诞妄景况下把车从头开回正轨。
近期,业内遍及感知到蔚来智驾智商有了进步,而在职少卿看来,这并非单点算法的突变,而是对“物理 AI 发展周期”有了全新通晓的截止。
任少卿将时期的发展分为四个阶段:方针不显露的第一阶段、存在弯说念超车可能的第二阶段、时期门道料理拼东说念主力的第三阶段,以及红利消失拼细节的第四阶段。
但到了 2023 年,跟着大模子和天下模子认识的涌现,任少卿判断智驾时期又了债到了饱读动底层转变的“第二阶段”。因此蔚来在两年前飘舞进行了组织架构的变革,将智驾团队重组成“4x100米致力于于跑”(预研、干线委用、跨平台适配、量产委用),并将资源倾注在了“第一棒”的预研上。
今天际界看到的“天下模子加闭环强化学习”带来的智商进步,其实这场架构变阵重叠 Infra 底座搭好的截止。
6月17日,36氪在中关村牛屋和蔚来任少卿过甚团队成员进行了相通,内容经裁剪:
问:当今许多汽车厂商王人在自研大算力芯片,为什么蔚来能率先在多平台落地?
任少卿团队:其实在激动自研芯片研发和量产的过程中(2024年流片,到2025年3月量产),咱们作念了多量的责任。固然友商布局也很早,在 AI Infra 层面,蔚来从2020年就运转布局了,尤其是自研了推理引擎、部署框架以及 AI 编译器。
恰是因为有了从2020年以来的这些积蓄,是以当咱们的自研芯片到位时,相关的工程遵守曾经达到了一定的高度。因此,在芯片流片转头之后,咱们很快就作念到了跨芯片平台的兼容。
问:近期对蔚来智驾的评价有所好转,为什么在这个时刻点专家能体验到版块和智商的昭彰进步?
任少卿:智驾智商的进步无非等于由三件事情组成的:新的算法、底层的硬件和底层的数据体系。
如果专家问最近这两年到底发生了什么,确乎是算法架构的变化(比如天下模子、闭环强化学习),然而在这些名义之下,更深层的原因是:咱们在 2023 年傍边通晓到,智驾的发展阶段跟前几年不太同样了。
专家看到的可能是从 Rule-base(基于规矩)酿成了端到端或者天下模子。但咱们看到的是物理 AI 发展阶段的倒退与重构。咱们界说时期的发展分为四个阶段:
在 2020 年傍边,其实智驾曾经进入了第三阶段,专家王人在拼堆东说念主、拼战略数目(写几万行代码)。但到了 2023 年傍边,跟着大模子时期的涌现,我认为智驾又了债到了第二阶段——咱们又不错运转用底层的时期转变来处罚问题、产生各异化了。
是以从阿谁时候运转,咱们不仅仅在作念新算法,也在作念组织架构的变革。约略两年前,咱们把组织架构酿成了雷同“4x100米致力于于跑”的神色:第一棒跑预研,第二棒跑干线景况委用,第三棒跑跨平台适配,2026世界杯赔率第四棒跑具体车型的量产委用。
因为时期发展了债到了饱读动转变的第二阶段,是以咱们在“第一棒(预研)”上插足了多量的资源。咱们交代了不同的预研团队,临了专家看到的宏不雅截止是“天下模子加闭环强化学习”,但在微不雅层面,咱们有许多转变来缓助这些架构的落地。这才是智商在这个节点爆发的底层逻辑。
问:当今智驾多是驳倒VLA和天下模子,竞争是不是有一个相对显露的趋势?
任少卿:算法有不同样的想法相称平淡,这亦然我合计东说念主工智能进入 AI 时期或者新时期时期最专诚道理味的点。如果专家王人走消释条路,那这个天下其实也不会发展这样快。
在往时三年,悉数这个词东说念主工智能发展相称快。我我方约略从16年就运转作念智驾,从2016年到2022年,智驾的算法,或者说物理天下的算法发展是很慢的,可能最大的变化等于 BEV,最多再加个 OCC,就没了。
然而从2022年运转,全体的时期又从相称细目变得相称不细目,涌现了多样各种的契机。咱们发布天下模子的时候是24年7月份,但里面运转研发是在23年下半年。那时候对“天下模子”的叫法还莫得那么显露,然而咱们的想法相比轻便:
第一,咱们但愿这个模子能用悉数无监督(unsupervised),或者自监督(self-supervised)的模式去作念磨砺,等于不需要再去标那么多的数据,况兼有些数据是你东说念主工标也标不出来的;第二,咱们但愿它能酿成一个多模态羼杂的模式,也等于统一的集合。
在往时三年,咱们又赶上了物理天下东说念主工智能快速变化的周期。专家从一个相称细目标、每天干的事情可能跟前三年基本没啥诀别的景况里跳出来了。就像原来写 Planning 模子、写 Planning 算法代码的同学,今天干的活儿比三年之前可能也等于多处理一些场景汉典。而当今,悉数这个词模子架构、磨砺架构,以及刚才说的数据工程架构,其实王人在一体化地发生大变革。
问:当今行业内其实有两种不太同样的模子适配神色。一种是拿着筛选后的数据从头训一个小模子;第二种神色是拿着训好的大模子,蒸馏出一个小模子。蔚来认为哪种神色是明天的发展标的?以及面前的作念法是什么?
任少卿:其实这两条路在之前的多样东说念主工智能模子发展中一直在不停切换。巧合候从头磨砺会更好,巧合候蒸馏出来的后果更好,这跟模子大小、磨砺模式王人相关系。对咱们来说,这两个王人是锻练的时期栈,是以咱们在模子上会具体评估,看针对刻下模子哪种模式后果更好。
对于咱们当今车端跑的这个模子来说,基本上接纳蒸馏的概率可能会更大一些。但我合计,这两者在骨子上对现存的算法体系不会产生太大的变化。
问:蔚来是否对一些竞品车型进行过体验,比如特斯拉 FSD,蔚来的 2.5 版块在行业内预期的身位约略是什么样?
任少卿:特斯拉确乎在数据体量和磨砺资源上是天下起先的,致使我合计它远雄壮于国内的公司,计较量上可能要超越一个量级以上。
单从架构的进程来说,咱们在本年上半年推出了基于天下模子的闭环强化学习,然后在这个版块里还会再加一个 SFT(监督微调),应该是不过时于特斯拉的,尤其在闭环这一块,咱们算是相比起先的。
问:今天讲了许多对于数据的问题,明天是否有可能发展到模子不再需要对数据的强依赖,不错通过更强的 AGI(通用东说念主工智能)智商,径直竣事更强的自动驾驶智商?
任少卿:数据才是这个时期 AI 的根源。专家看到,除了算力的进步除外,包括端侧算力、云表算力,在往时5-10年进步了相称多,致使是百万倍的进步。然而悉数的基础模子,包括大谈话模子、智驾,以及背面可能更新的一些模子,最根底的问题如故数据。
作念谈话模子不错把互联网的数据径直下载下来,轻便作念一个清洗,就有几十T致使更高量级的数据。然而其他悉数的诓骗王人需要我方产生数据,王人需要我方去处罚数据获得的问题,尤其是智驾。
智驾要处罚的问题等于:起先,要能产生这样大的数据量;第二,要能产生等价于 10 亿网民作念筛选的截止。我昭彰莫得这样多东说念主工去干这个事,是以只可通过自动化了。
惟有当这类既有庞杂体量、又明确包含了 Corner Case 的数据产生之后,神经集合才调推崇它的作用。因为直到今天,大模子和神经集合依然是“Data Hungry”(数据饥渴)的,况兼越大的模子,对数据的饥渴程度越强。是以,咱们必须在物理天下竟然切环境里去处罚数据的问题。
问:业内有一种说法认为,“如果一个自动驾驶只会开车,那么它是开不好车的”。这个您怎么看?意道理味可能是需要加入其他一些“通识”的数据让这个模子的智商进一步进步。您合计这种说法有趣味吗?
任少卿:这其实分为两个部分。第一是有更多其他起原的数据,比如咱们也会用一些互联网数据,这主如果为了增多一些场景的粉饰度。
第二等于所谓的“通识”。对于东说念主来说,咱们学开车所谓的“通识”实践上等于学交规。在这些层面上,其实有两种让 AI 学习的模式:
一种模式是把大谈话模子加进去来处罚这个问题,我合计这个标的灵验,但在今天而言,这条路还并不是主流门道。
咱们面前的处罚神色实践上是通过闭环强化学习的模式,让模子明确地知说念:你不成压白线,你不成闯红灯;或者更好的一种情况2026世界杯欧赔,如果智驾系统看到红灯倒计时还有 2 秒,那它不错无谓把刹车踩得那么死。通过这种在系统闭环里不停试错、强化学习的模式去拿截止,面前来看更高效,后果也更好。
 备案号:
备案号: